The Idea Maze of Personal Logging
In another post, I laid out my reasons for building a personal logging system. Here, I’ll go into the strategy and tactics issues.
Like many projects, personal logging can extend into a very large project. Unless you intentionally limit its scope (at least in the beginning), it’ll spiral into a mess of code that won’t ever be useful. If you can quickly build a small subset of the final product that is either useful or interesting, the project is much more likely to succeed (cf. MVP).
Let’s explore the idea maze of approaches to building a personal logging system.
Logging vs analysis
The two main parts of a personal logging system are the data collection and analysis. Analysis without data is impossible, so it makes sense to start with the collection. On the other hand, blind collection without reference to the later analysis phase is likely to result in collecting the wrong data. As mentioned in my earlier post, a significant work item is to determine exactly which facts are narratively interesting and log those only.
Conclusion: start with collection, but try to quickly get that to a basic level so that you can begin to perform rudimentary analysis on it.
Automatic vs manual logging
As far as collecting data, there’s two main ways to do it: automatic and manual. Automatic collection is convenient, but it has a tendency to gather whatever data is easy to collect instead of what’s narratively interesting. Additionally it’s somewhat harder to implement than a manual system. In particular, it requires integration with either hardware (usually in a phone) or the users’ other services.
Manual collection is easier to implement, because it puts more of the burden on the user. More importantly, with manual collection, we can be very flexible about which things we record. This allows us to experiment and determine which things are interesting and which are not. We’ll avoid much of the temptation to only record those things which are easy to record because most things will be easy to record. The downside is, of course, that the user now has the burden of journaling in a consistent manner and determining which things they want to record. For an MVP-like prototype, though, giving manual work to get flexibility and development speed is a fair trade.
Conclusion: start with manual collection. Eventually some automatic collection will be used, but I doubt we’ll ever be able to eliminate manual collection.
Data structure
If we’re manually collecting data, what structure should it have? You should be able to add to a log by adding a “fact” or “event”. But if the log has too rigid a structure, then it’s awkward to put all the differnet kinds of information in it. If it has too flexible a structure, it’s likely to become an unorganized mess of information that’s hard to input and hard to analyze.
On the “too rigid” side, we have things like “list of records of [agent action
time place purpose instrument]”. This is a bad choice because not all facts we
learn will have each of those fields (or some of the fields will not be
interesting), and also because sometimes other modifiers are relevant that can’t
be encoded into that structure.
On the “too flexible” side, we have things like “plain text” or (unrestricted) JSON. These are very general structures that don’t give very many guarantees about the structure of the data. It’s easy to input this sort of data, but it’s very difficult to parse meaningful insights from it.
In the middle ground, an option is to take a cue from linguistics and store a
list of facts, where each fact is a sentence of the form [subject verb
list-of-modifiers], where each modifier is a pair of a tag (usually a
preposition or other adposition) and an object. If the tag is empty, then the
object is a direct object. Thus, a fact like “i ate a burrito for breakfast at
8am this morning” would be represented as:
subject => "i"
verb => "ate"
modifiers =>
_ "a burrito"
for "breakfast"
at "8am this morning"
It’s fairly easy to input this sort of data, and it’s fairly easy to analyze it. If you recorded this sort of sentence every morning (and maybe the program should prompt you to do so), then to get a list of common breakfast items, you could search for the direct objects in all facts with subject “i”, verb “ate”, and a modifier “for breakfast”. You can similarly tell things like when you tend to eat, and so forth.
Are there other possible structures? Sure, but this seems like as good of a structure to start with as any. Possible extensions include prompting the user to fill in common modifiers once they’ve entered the verb, or even (if more structure is desired), requiring certain verbs to have certain modifiers.
Conclusion: List of facts, each of which is a triple of a subject, verb, and list of modifiers, and each modifier is a tag (usually a preposition) and an object.
Platform
Web, mobile, desktop, or all three?
A purely mobile system is bad because if you lose your phone (or it’s destroyed or whatever), then you lose your data. Additionally, analysis on your phone is unlikely to work well, and data input may not be all that convenient compared to quickly typing on a desktop.
A purely desktop system is bad because you want to be able to log on-the-go, and you eventually want to be able to access a phone’s hardware for more automated logging (although we really shouldn’t be thinking about that yet).
A web system seems to give the best of both worlds, since it can be accessed from all your devices, and eventually a native mobile app could be built for further integration. A native desktop app could also be built, for that matter.
On the web, it could either be a cloud service or one you run on your own server. In my other post, I detailed the reasons why a centralized cloud service isn’t acceptable to me. This means that you’ll have to run it on your own server for now.
Running your own server usually paying $5/month to Amazon or Digital Ocean and being the sysadmin for a Linux server. Many developers already have servers, so it’s not a problem. For a broader set of people, though, this would be prohibitively hard.
For an MVP it works, and that’s all we’re looking at now, but it’s worth taking a second to understand that you can also get around the problems with centralization (privacy, security, and not having full control of the data) while gaining its benefits. If you fully encrypt the data client-side and do all processing on the client side (there shouldn’t be that much processing, right?), then the data on the server is unreadable by anyone but authorized clients. This isn’t possible for many services, but here the server really is just a data store. This suggests a future where you pay a few bucks a year to someone to host your data. The scheme of “I pay you for goods and services” has a long and glorious tradition, and it’s much better when not complicated by showing you ads and collecting your personal data for nefarious purposes.
Conclusion: Make it a web app, hosted on your own server for now. Eventually build native apps, but you want the data stored in the cloud (either your own or encrypted on someone else’s).
Conclusion
So, we’re going to start by building a web app to manually collect a list of facts so that we can start analyzing as soon as possible. Cool. Here’s a prototype: philipcmonk / plogging
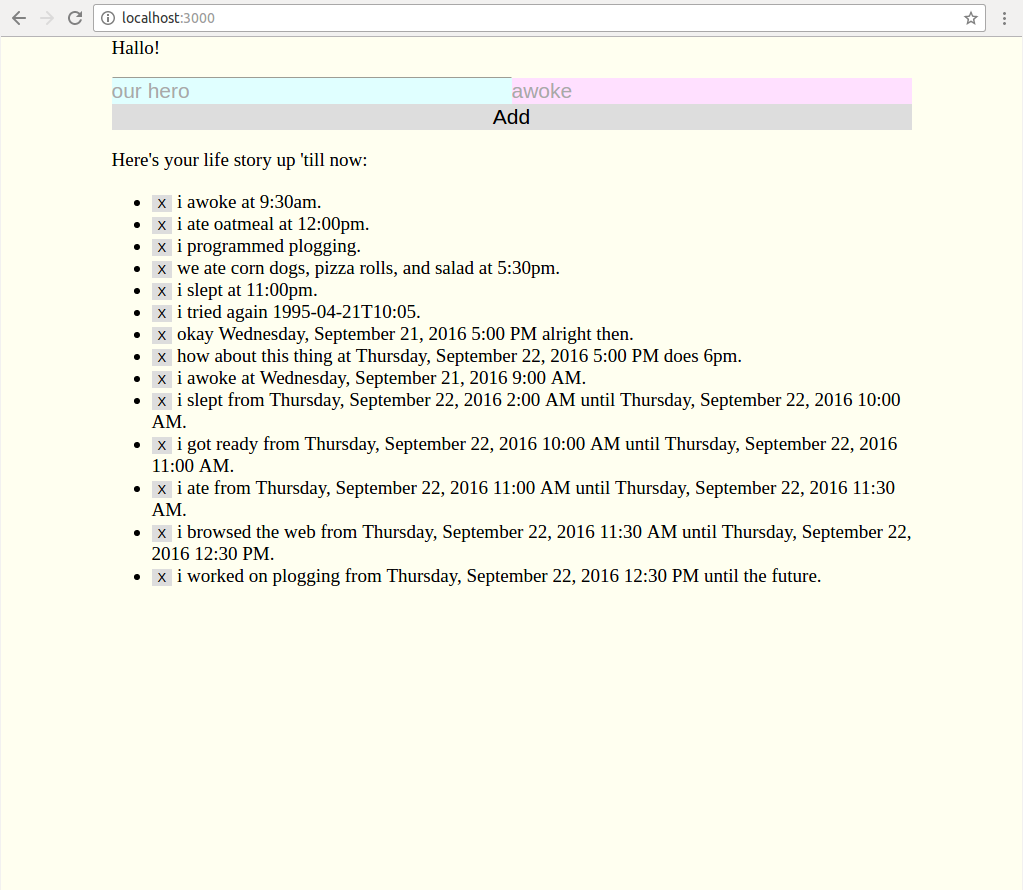
It may be painfully obvious there that I’m no designer, and am also colorblind. Also, the name needs work. Actually, most all of it needs work. Any and all help is appreciated!